
Trustworthy AI

Multilingual AI Teaching Assistant Trained on the Content of this Website.
This website is a proof-of-concept of trustworthy, multilingual, generative artificial intelligence (AI) in higher education. The proprietary, custom-trained AI Teaching Assistant is not only multilingual but also adaptive. It customizes its answers to match students’ levels, taking hint from how questions are phrased. It can also engage in role-playing to personalize learning.
Here are some tips to get the most out of the AI Teaching Assistant. Since it generates prompt-based outputs, you can use magic words, also known as boundary-setting instructions, such as “according to Professor Joubin,” “according to the chapter on __,” “according to the screenplay of ___,” or “in this course” to retrieve specific information from the dataset the AI is trained on. These magic words will be the AI’s cue to retrieve contextual-specific information regarding a critical concept.
The AI assistant’s dynamic and multilingual outputs are tailored to each student’s level, taking a cue from the ways in which students frame their questions. It offers a personalized learning experience. Every student enjoys a unique educational approach that’s tailored to their individual abilities and learning styles. Research shows that personalized learning increases student motivation and engagement with course material.
Trustworthiness is defined according to the National Institute of Standards and Technology (NIST) in terms of a model’s explainability, interpretability, accountability, and transparency.
Explainability: The AI tutor’s operation is explainable through the Retrieval-Augmented Generation (RAG) method. It draws answers from within the crawled data of this website as well as transcripts of the videos as a pre-set boundary. Further, the AI tutor’s operation is interpretable through iterations of custom prompts in the background and custom data sets (this website’s content).
Interpretability: The embedded chat bubble interface is programmed in HTML code. The chatbot’s operational information and training is managed using Vercel database. When users interact with the AI tutor chatbot, the server hosting this site makes calls to OpenAI to facilitate the chatbot interactions. The same server also hosts the Next.js application for the chatbot interface.
Transparency: The Next.js code for our AI is open source (see GitHub). Akhilesh Rangani used JavaScript, Psima, TypeScript, and Next.js framework to design the trustworthy AI features for this website. The model was trained on a pre-defined dataset containing the content of this online textbook and utilizes OpenAI’s APIs to craft responses.
Ethics: This project emphasizes AI and social justice. The use of AI on this site, from search algorithms and AI reader to AI tutor, models best practices in civic science, a partnership between scientists and the public as stakeholders in co-creating technologies for public good in a democratic society (see also Tufts University’s definition).
Our system does not store user data. When users interact with the AI tutor on this site, the messages shared between the chatbot and the user are deleted as soon as the user closes the chatbot screen. Data is kept private and not used by AI vendors to train their LLM, though the data may be retained for up to 30 days to prevent abuse. Our system uses the Assistants API from OpenAI. Data sent via that API is not used to train their models (see also Enterprise Privacy policy). Being fully SOC 2 compliant, the system encrypts data in transit and at rest, and limits data retention, which helps reinforce privacy.
Trustworthiness is a relational property, namely a characteristic of an object (such as AI). Trust is an attitude humans have towards people or tools that may be trustworthy. Read more on the epistemology of trust in Carolyn McLeod’s “Trust” in the Stanford Encyclopedia of Philosophy, ed. Edward N. Zalta & Uri Nodelman (2023).
System architecture
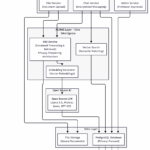
Flow chart showing how professors create course-specific chat bots like the one on this site
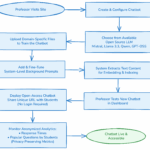
Flow chart showing how students use this open-access AI

Areas for Further Investigation: How does trust, or the lack thereof, affect learning outcomes? How does trust among human agents form? How does trust form between human agents and tools? How might educators mange overtrust and undertrust?
It is important to include humanistic perspectives in current debates about generative AI, because the humanities offer effective tools to examine trust and society’s relationship with technology. Maintaining scholarly integrity benefits the public and upholds research trustworthiness.
Learn more about Joubin’s open-access AI:
- Joubin, Alexa Alice. “Enhancing the Trustworthiness of Generative Artificial Intelligence in Responsive Pedagogy in the Context of Humanities Higher Education” (2024) DOI: 10.1007/978-3-031-65691-0_11
- Fostering trust in AI-powered tools for education: An interview with Alexa Alice Joubin, JSTOR Blog, April 2, 2025
- AI-Powered Teaching Assistants Can Drive Student Success, EdTech: Focus on Higher Education, March 24, 2025
- Joubin, Alexa Alice. Meta-Cognition and Open-Access Large Language Model, ITHAKA webinar, February 2025 (YouTube)
This website exemplifies public interest technology (PIT), the application of technology to advance the public good and to make existing systems more inclusive. Generative artificial intelligence (AI) is one of the most significant forms of public interest technology. Driven by machine learning models, these text-and-image-generating mechanisms impact all sectors of our society.
The proprietary AI here is multilingual, adapts to users’ levels, and enhances dynamic, personalized learning. Algorithm-governed inquiries and responses frame our contemporary life from navigation to higher education. If students are already using AI, it is better to use the professor’s proprietary AI rather than a general-purpose model.
This resident AI assistant cannot search the web. While some for-profit generative AI platforms can perform live searches of the Internet, the API, as currently implemented, does not support live web search capabilities through system prompts (see discussion on developer forum).
Further, this site makes a point of not using AI-generated images except for very rare instances to demonstrate the harm caused by AI images. This is part of Professor Joubin’s ethical principle. Since AI models cannot acknowledge and give credit to its sources, AI-generated images are unethical. Stock photography company Getty Images sued Stable Diffusion for copyright infringement. Artists developed a new tool to add invisible watermarks to protect their work from being used to train AI models.
As the founding co-director of the GW Digital Humanities Institute, leader of several large-scale public interest technology (PIT) projects, the PI and co-PI of several external PIT grants, as well as the inaugural Public Interest Technology Scholar, Alexa Alice Joubin has worked closely with colleagues and students across STEM, humanities, and interpretive social sciences on advancing the fields of humanistic AI, data justice, bias detection, digital cultures’ relationships to disability cultures, and empowering minority students through public interest technology.
